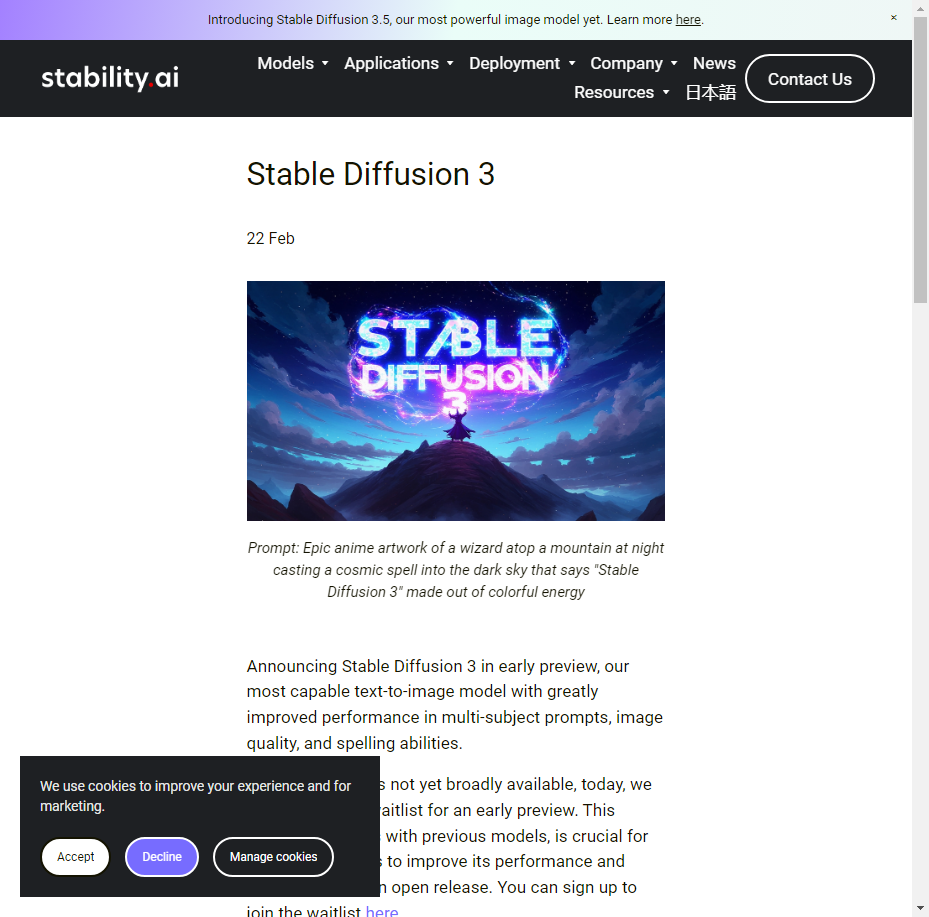
Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.